

With the New Year comes the first update to version 1.0 of the Griptape Framework. The 1.1 release is focused on introducing new features that simplify the experience for developers building LLM-powered applications with Griptape, as well as adding support for performance evaluation and for a feature specific to Anthropic and Amazon Bedrock. Let’s dive straight in…
More control over Conversation Memory
The 1.1 update brings the ability to control whether conversation memory should be created and maintained at the per-structure or per-task level. By default, Conversation Memory Runs are created for each run of a structure. Griptape takes a Structure's input_task input and the output_task output, storing them in the Conversation Memory for the Run. Tasks that are neither the input task nor the output task are not stored in the Conversation Memory for the Run. This approach allows you to perform work within a Structure without it being stored in, and potentially cluttering, Conversation Memory.
With this new feature, you can now set conversation_memory_strategy = "per_task". With this option, Conversation Memory is created for each Task when it runs. This eliminates the need to feed the output of Tasks into each other using context variables like {{ parent_output }} as the output of the previous Task is stored in Conversation Memory and loaded when the next Task runs. To blend the two approaches, you can disable storing output into Conversation Memory for individual Tasks by setting PromptTask.conversation_memory to None for specific Tasks.
This provides developers with fine-grained control over Conversation Memory for multi-step Structures such as Pipeline Structures.
Branching logic in Workflow Structures
With the addition of branching logic to Workflow Structures, developers can now add logic to workflows enabling them to selectively skip tasks in a workflow. The newly introduced BranchTask task type is used to manage tasks that can branch into multiple child tasks, ensuring that only valid child tasks are executed and others are skipped.
In the sample application below, we have created a simple review processor for a hotel. Using the StructureVisualizer from griptape.utils we can generate a visualization of this simple workflow.
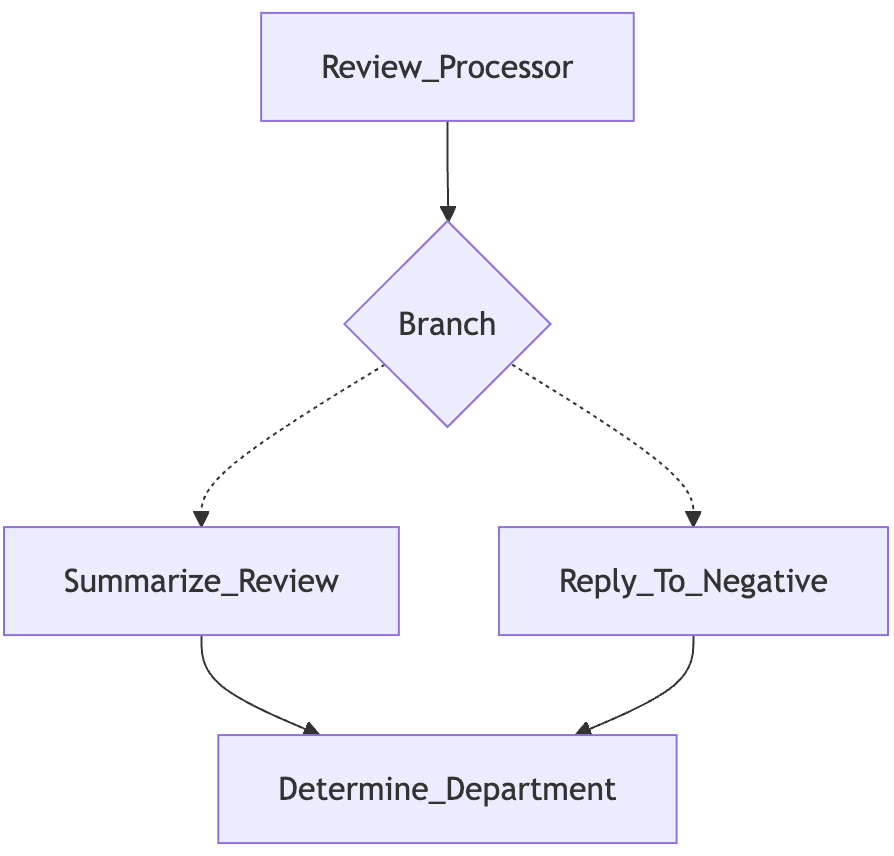
In the Review_Processor step, we evaluate whether new reviews are positive or negative in sentiment before branching to either create summary headlines of positive reviews for the hotel’s mobile app or to generate responses for negative reviews. The workflow converges for the final step where we determine which department in the hotel the review is most relevant to, so they can get the kudos from a happy guest, or address any issues identified in a negative review.
This example also makes use of per_task Conversation Memory, which allows the tasks in the latter stages of the pipeline to refer back to the review text provided at the start of the Structure Run.
from griptape.artifacts import InfoArtifact
from griptape.structures import Workflow
from griptape.tasks import BranchTask, PromptTask
from griptape.utils import StructureVisualizer
def on_run(task: BranchTask) -> InfoArtifact:
if "POSITIVE" in task.input.value:
return InfoArtifact("summarize_review")
else:
return InfoArtifact("reply_to_negative")
workflow = Workflow(
conversation_memory_strategy="per_task",
tasks=[
PromptTask(
"Determine whether this review is positive or negative and state POSITIVE or NEGATIVE: '{{ args[0] }}'",
child_ids=["branch"],
id="review_processor",
),
BranchTask(
"{{ parents_output_text }}",
on_run=on_run,
id="branch",
child_ids=["summarize_review", "reply_to_negative"],
),
PromptTask(
"Summarize the review down to less than 10 words",
id="summarize_review",
child_ids=["determine_department"],
),
PromptTask(
"Write an apologetic reply",
id="reply_to_negative",
child_ids=["determine_department"],
),
PromptTask(
"Which department is the review most relevant to? Options are: FRONT OFFICE, BUILDING MAINTENANCE, HOUSE KEEPING, FOOD AND BEVERAGE, POOL AND GROUNDS",
id="determine_department",
),
],
)
print(StructureVisualizer(workflow).to_url())
workflow.run(
"The hotel exceeded my expectations in every way. From the moment I arrived, I was impressed by the welcoming atmosphere and attentive staff. One of the highlights of my stay was the pool—it was not only well-maintained but also wonderfully warm, making it perfect for relaxing after a long day. The overall experience was truly enjoyable, and I would highly recommend this hotel to anyone seeking comfort and excellent amenities."
)
workflow.run("The hotel was awful. There were bugs in my bed")Evaluate LLM performance with EvalEngine
Engines are Griptape’s way of packaging up common capabilities that are available across different LLMs and LLM providers, such as Retrieval Augmented Generation (RAG), summarization, and now evaluation. With the addition of EvalEngine to the Griptape Framework, developers can evaluate the performance of an LLMs output for a given input.
EvalEngine requires either evaluation criteria or evaluation steps to be set. If evaluation criteria are provided, Griptape will generate evaluation steps for you. This provides a simple way for developers to get started quickly with evaluation. For more complex evaluations, developers can define their own evaluation steps.
The code sample below shows how you can access the generated evaluation steps to review them. When the sample is run, the default model, which is OpenAI's gpt-4o, responds that a greenhouse is made of glass, and uses the generated evaluation steps to report an evaluation score of 1.0, which is the maximum. This indicates that the output is considered accurate when evaluated using the generated evaluation steps.
import json
from griptape.engines import EvalEngine
engine = EvalEngine(
criteria="Determine whether the actual output is factually correct based on the expected output.",
)
score, reason = engine.evaluate(
input="If you have a red house made of red bricks, a blue house made of blue bricks, what is a greenhouse made of?",
expected_output="Glass",
actual_output="Glass",
)
print("Eval Steps", json.dumps(engine.evaluation_steps, indent=2))
print(f"Score: {score}")
print(f"Reason: {reason}")
% python3 eval_engine_test.py
Eval Steps [
"Compare the actual output to the expected output to identify any discrepancies in factual information.",
"Verify each fact in the actual output against the corresponding fact in the expected output to ensure accuracy.",
"Assess whether any additional information in the actual output is consistent with the context provided by the expected output.",
"Determine if the actual output fully addresses the requirements outlined in the expected output."
]
Score: 1.0
Reason: The actual output 'Glass' matches the expected output 'Glass' perfectly, with no discrepancies or additional information needed. It fully addresses the requirements outlined in the expected output.
Loaders now have a .save() method
Handling artifacts has been simplified with the addition of a save method to BaseFileLoader. This makes it easier for developers to persist data and removes the requirement to import additional dependencies such as PathLib to handle save operations for artifacts.
from griptape.artifacts import TextArtifact
from griptape.loaders import TextLoader
# Directly create a file named 'sample1.txt' with some content
filename = "sample1.txt"
content = "content for sample1.txt"
text_loader = TextLoader()
text_loader.save(filename, TextArtifact(content))Stream events from Structures as an iterator
You can now process events from a Structure Run as an iterator using Structure.run_stream()
from griptape.events import BaseEvent
from griptape.structures import Agent
from datetime import datetime
def format_time(time: float) -> str:
return datetime.fromtimestamp(time).strftime('%d-%m-%Y %H:%M:%S.%f')[:-3]
agent = Agent()
for event in agent.run_stream("Hi!", event_types=[BaseEvent]): # All Events
print(format_time(event.timestamp), type(event)) Adding support for GenericMessageContent for Antrophic and Amazon Bedrock Prompt Drivers
Developers can now use the Griptape Framework to take advantage of the features within Anthropic and Amazon Bedrock that offer the ability to pass documents directly to the LLM along with a prompt. This provides developers with a quick and simple way to use these LLMs to perform operations on documents such as summarization or extracting facts, and even to build chat applications that allow users to talk to a document.
To use this feature, set the input of the PromptTask to be a GenericArtifact with "type": "document" as shown in the fact extraction example here.
doc_bytes = requests.get("https://arxiv.org/pdf/1706.03762.pdf").content
agent = Agent(
tasks=[
PromptTask(
prompt_driver=AnthropicPromptDriver(
model="claude-3-5-sonnet-20240620", max_attempts=0
),
input=[
GenericArtifact(
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": base64.b64encode(doc_bytes).decode("utf-8"),
},
}
),
TextArtifact("What is the title and who are the authors of this paper?"),
],
)
],
)Other changes & fixes in Griptape 1.1
This release also adds the capability to save and load Rulesets, ToolkitTask.tools and PromptTask.prompt_driver independently of structures with the addition of serialization and deserialization for these resource types.
PromptTask has been extended and now takes tools as a configuration parameter. With this change, PromptTask can now do everything that a ToolkitTask can do. Developers can continue to use ToolkitTask for now, but it will be removed in a future version so you should update your applications to use PromptTask.
For a full list of the all the fixes included in the Griptape 1.1 release, please head over to the CHANGELOG for the Griptape Framework at https://github.com/griptape-ai/griptape/blob/main/CHANGELOG.md
How to get started
Griptape 1.1 is available on PyPi now and you can download it with pip, poetry, or another Python package manager of your choice. We would love to hear your feedback on the changes and new features.