

Griptape is a modular open source Python framework that allows developers to build and deploy LLM-based agents, pipelines, and workflows. Its composability makes it ideal for creating conversational and event-driven AI apps that can access and manipulate data safely and reliably.
- What is Griptape?
- Working with Data
- Connecting AI Agents to Data
- Dynamic Agents And Off Prompt Data
- The Road Ahead
In this blog post, we will first dive into the logic behind the framework abstractions and then transition into building several useful AI agents. The following sections focus on the high-level framework design. If you have more specific questions, please refer to the docs. To get your environment setup, please check out the quick start guide on GitHub. Now, let’s dive in!
What is Griptape?
The Griptape framework provides developers with the ability to create AI systems that operate across two dimensions: predictability and creativity. For predictability, Griptape enforces structures like sequential pipelines, DAG-based workflows, and long-term memory. To facilitate creativity, Griptape safely prompts LLMs with tools and short-term memory connecting them to external APIs and data stores. The framework allows developers to transition between those two dimensions effortlessly based on their use case.
Griptape not only helps developers harness the potential of LLMs but also enforces trust boundaries, schema validation, and tool activity-level permissions. By doing so, Griptape maximizes LLMs’ reasoning while adhering to strict policies regarding their capabilities.
Griptape’s design philosophy is based on the following tenets:
- Modularity and composability: All framework primitives are useful and usable on their own in addition to being easy to plug into each other.
- Technology-agnostic: Griptape is designed to work with any capable LLM, data store, and backend through the abstraction of drivers.
- Keep data off prompt by default: When working with data through loaders and tools, Griptape aims to keep it off prompt by default, making it easy to work with big data securely and with low latency.
- Minimal prompt engineering: It’s much easier to reason about code written in Python, not natural languages. Griptape aims to default to Python in most cases unless absolutely necessary.
With Griptape, developers can quickly build modular AI agents in Python without having to tinker with LLM prompts. Additionally, they can implement complex ETL-like flows without data ever reaching the prompt.
Let’s first explore Griptape by looking at the data framework primitives and then transition into building agents, pipelines, and workflows.
Working with Data
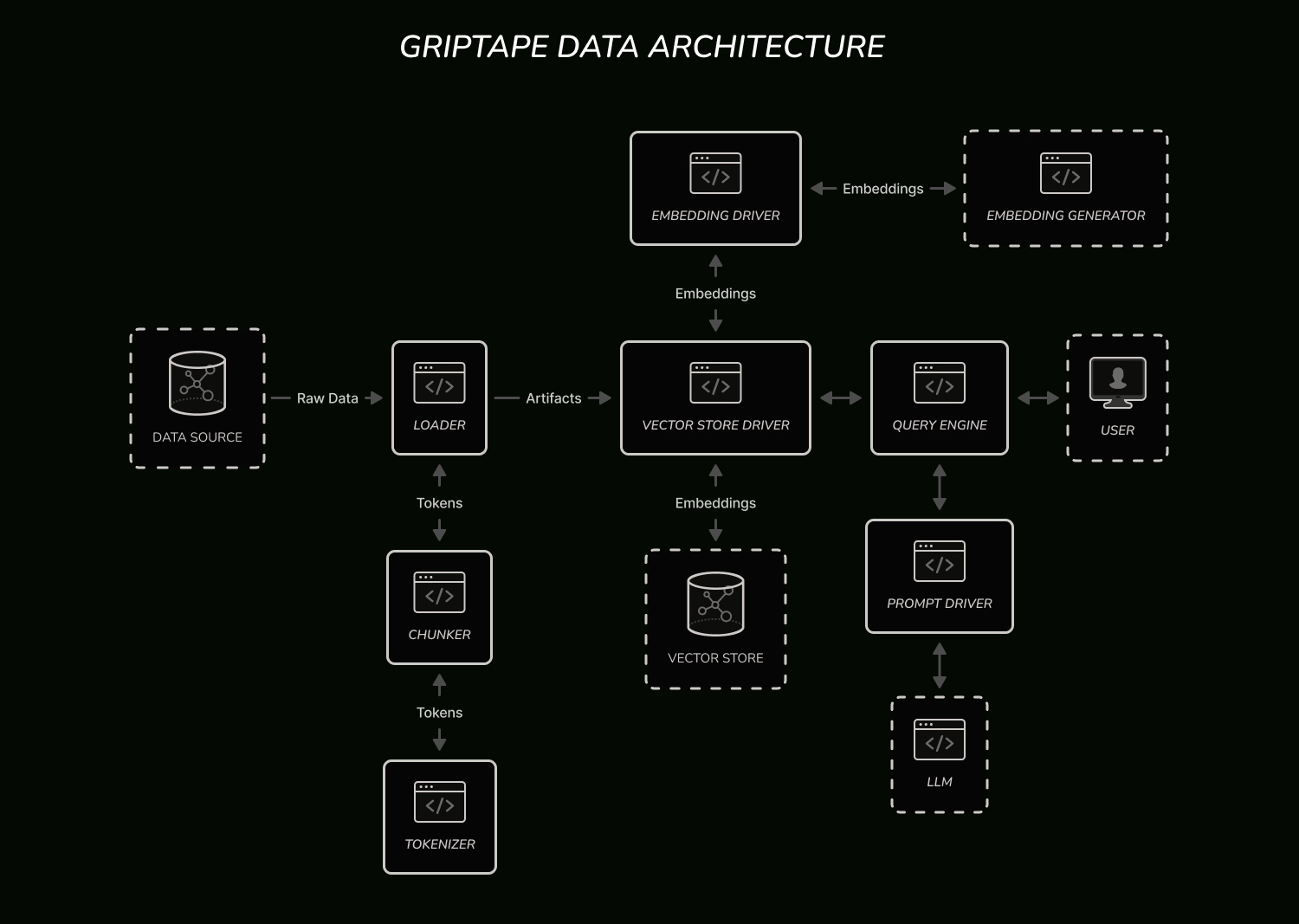
Griptape offers several abstractions for working with data. Those include:
- Artifacts: Used for passing data of different types between Griptape components. There are artifacts for passing raw text, blobs, CSV rows, errors, and info messages.
- Embedding drivers: Used for generating vector embeddings from text. Embeddings are lists of numbers that represent the meaning and the context of the tokens that LLMs process and generate.
- Tokenizers: Used for encoding and decoding text into tokens. Tokens are pieces of text used by LLMs to process and generate language.
- Vector store drivers: Used for storing and searching embeddings in vector databases.
- Chunkers: Used for splitting texts into tokens. Griptape includes chunkers for different text shapes: regular text, PDFs, markdown, and more.
- Loaders: Used for loading textual data from different sources. Griptape provides loaders for regular text, PDFs, SQL stores, websites, and more.
- Query engines: Used for running natural language search queries via LLMs on chunked text (with contextual metadata) loaded from vector stores.
- Prompt drivers: Used for processing prompts in different LLMs.
Here is a high-level diagram of how all of those components fit together:
Now, let’s put it into practice and write a simple app that loads a webpage into an in-memory vector store:
Here we use the WebLoader to load a webpage and split it into 100 token long chunks in the form of TextArtifacts. Then we upsert those artifacts into the in-memory vector store and finally query it with the VectorQueryEngine. The output of the query looks like this:
Griptape is an opinionated Python framework that enables developers to fully harness the potential of LLMs while enforcing strict trust boundaries, schema validation, and activity-level permissions […]
By default, vector store drivers use the OpenAiEmbeddingDriver, so you’ll need to have OPENAI_API_KEY on your path for this example to work. You can also pass a custom embedding driver if you wish to use a different backend for embeddings generation.
The same approach can be applied to loading a directory of PDF files:
Here we load PDF files from a specific directory, upsert them into the vector store, and finally query them with the VectorQueryEngine. Notice how we don’t have to specify the namespace when we load multiple documents—each document gets an automatically generated namespace.
Connecting AI Agents to Data
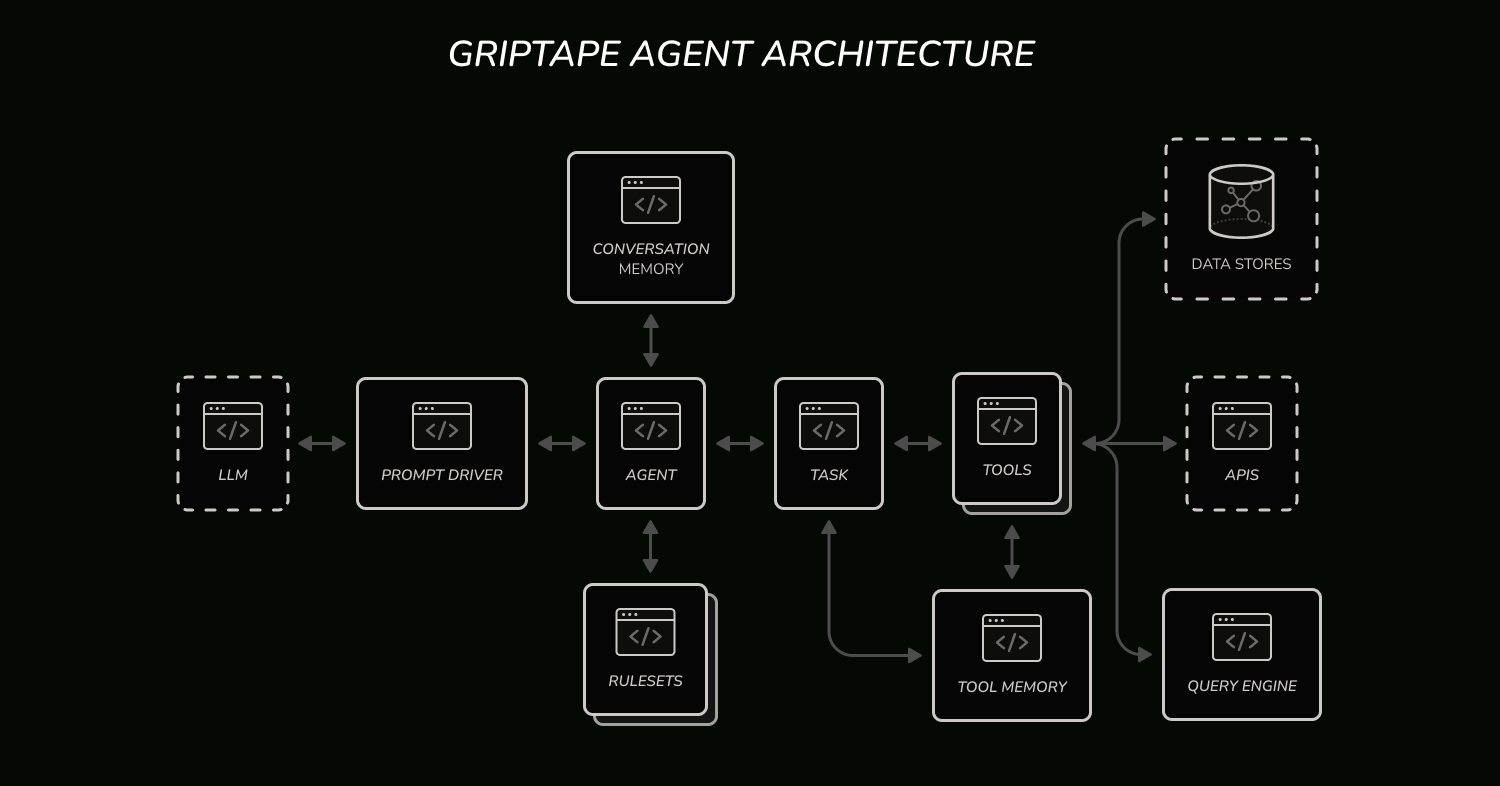
Built on top of the data framework, agents are Griptape structures designed for easy data integration into large language models (LLMs). In addition to agents, Griptape supports pipelines and workflows. All structures use tasks to execute queries against LLMs. Agents always execute just one task. Pipelines string together multiple tasks and execute them sequentially. Finally, workflows organize tasks in a DAG and execute them in parallel. For the rest of this post, we’ll focus on agents and cover other structures in the future.
Agents (or any other structure for that matter) can be used to connect your pre-processed data to LLMs via tools. Griptape tools are Python classes with activities. Activities are Python methods decorated with the @activity decorator. Each activity has a description (used to provide context to the LLM) and the input schema that the LLM must follow in order to use the tool. Griptape validates LLM outputs against the schema to ensure each tool activity is used correctly.
We provide a repository of official tools for accessing and processing data. You can also build tools yourself. For example, here is a simple tool for generating random numbers:
Now, let’s build an agent that accesses pre-processed webpage data from the previous example via tools:
Here we instantiate the KnowledgeBaseClient tool that wraps the query engine and enables the LLM to search knowledge bases. We then initialize an agent with that tool and start a CLI chat.
Upon initialization, agents instantiate conversation memory used to preserve the conversation flow. Griptape supports different types of conversation memory, such as BufferConversationMemory and SummaryConversationMemory, which are useful in different scenarios.
Finally, agents can be configured with RuleSets of Rules. The purpose of rules is to steer agents and other structures without having to write out new prompts. This can be useful when defining agents “personas” or needing the agent to format output in a specific way.
Here is how we can further modify our agent to follow rules and use custom memory:
Here is a diagram of how the different agent components fit together:
Dynamic Agents And Off Prompt Data
Now, let’s do something different. Up until this point, we worked with pre-processed data, but what if we need the agent to load data dynamically and work with it at runtime? Griptape makes it possible by integrating tools and short-term memory.
At a high level, every tool returns an artifact or a list of artifacts. That output can go back to the LLM, but it’s often undesirable for several reasons:
- The output is too long, which exceeds the prompt token limit, increases latency, and reduces model precision.
- Your data should never leave your cloud account or be injected into the prompt.
Griptape has a way to store every tool output in the short-term memory, called BaseToolMemory (with available variants for text and blobs), which the LLM can then use to search through, summarize, or plug it back into other tools that support tool memory. By default, Griptape wraps tool activities with tool memory (unless, an activity explicitly disables it).
Here is an example of a dynamic agent that can query a SQL table, answer questions about that table, and store full query outputs on disk without them ever being loaded into the prompt.
Here we initialize an agent with three different tools. The FileManager can read and write files from disk. The SqlClient tool can execute queries with results going into tool memory. Tool memory has activities that enable the LLM to query, summarize, and extract data.
Let’s try running a complex query like this:
search for all items under $20 and store them in cheap-items.csv
Here is what happens in Griptape under the hood:
- First, the LLM uses the SQL tool to run a statement like
SELECT * from items WHERE price <= 20;. The tool automatically provides the schema to the LLM, so it doesn’t have to guess about column names. - Once the tool returns the output, Griptape stores it in the default
TextToolMemoryand tells the LLM where it was stored. - The LLM then makes a request to the
FileManagertool to move the output incheap-items.csv. The tool recognizes the CSV nature of the output and writes CSV rows to the file.
Playing around with this example and trying out different queries should give you a good idea of what kinds of creative LLM workflows Griptape enables.
The Road Ahead
Developers are already deploying Griptape agents, workflows, and pipelines in production. The open source framework that we started earlier this year is getting better by the day. Over the next few months we are focusing on building a managed platform for deploying, managing, and running Griptape apps at scale in any cloud. If you are interested, please leave your email on our signup form.